Madhu Vankadari is a doctoral candidate at the University of Oxford's Cyber Physical Systems group, under the supervision of Prof. Niki Trigoni
and Prof. Andrew
Markhem to Oxford, he worked as a Machine Vision researcher at TCS Research in India. Madhu's research revolves around using deep learning for SLAM-related challenges, such as improving depth estimation, camera pose accuracy, multi-motion scenarios, and visual place recognition. His work finds applications in robotics and computer vision, enhancing areas like autonomous navigation and augmented reality.
I worked with many robots such as Manipulators, Ground and Aerail Vechicles. I
aim to make these robots a little bit safer than today.
Currently, I am working on large-scale localization and mapping problems which
has potential applications in Autonomous Driving, Augmented and Virtual Reality
areas.
W§e introduce an algorithm designed to achieve accurate self-supervised stereo depth estimation
specifically for nighttime conditions. Our approach efficiently utilizes features extracted by
a pre-trained visual foundation model
Self-supervised depth estimation algorithms rely heavily on frame-warping relationships,
exhibiting substantial performance degradation when applied in low-visibility and noisy
nighttime scenarios with varying illumination conditions. Addressing this challenge, we
introduce an algorithm designed to achieve accurate self-supervised stereo depth estimation
specifically for nighttime conditions. Our approach efficiently utilizes features extracted by
a pre-trained visual foundation model. We also present an efficient technique for matching
and integrating features from stereo frames. To prevent pixels that sufficiently violate pho-
tometric consistency assumptions from adversely affecting subsequent depth predictions,
we propose the utilization of a novel masking approach designed to filter out such pix-
els. Addressing weaknesses in the evaluation of current depth estimation algorithms, we
propose novel evaluation metrics. Our experiments, conducted on demanding datasets in-
cluding Oxford RobotCar and Multi-Spectral Stereo, demonstrate the robust improvements
realized by our algorithm
In this paper, we propose a new self-supervised mobile object detection approach called SCT. This uses both
motion cues and expected object sizes to improve detection performance, and predicts a dense
grid of 3D oriented bounding boxes to improve object discovery
Deep learning has led to great progress in the detection of mobile (i.e.
movement-capable)
objects in urban driving scenes in recent years. Supervised approaches
typically require the
annotation of large training sets; there has thus been great interest in
leveraging weakly,
semi- or self-supervised methods to avoid this, with much success. Whilst
weakly and
semi-supervised methods require some annotation, self-supervised methods
have used cues such as
motion to relieve the need for annotation altogether. However, a complete
absence of annotation
typically degrades their performance, and ambiguities that arise during
motion grouping can
inhibit their ability to find accurate object boundaries. In this paper, we
propose a new
self-supervised mobile object detection approach called SCT. This uses both
motion cues and
expected object sizes to improve detection performance, and predicts a dense
grid of 3D oriented
bounding boxes to improve object discovery. We significantly outperform the
state-of-the-art
self-supervised mobile object detection method TCR on the KITTI tracking
benchmark, and achieve
performance that is within 30% of the fully supervised PV-RCNN++ method for
IoUs <= 0.5.
Self-supervised deep learning methods for joint depth and ego-motion
estimation can yield accurate trajectories without needing ground-truth
training data. However, as they typically use photometric losses, their
performance can degrade significantly when the assumptions these losses make
(e.g. temporal illumination consistency, a static scene, and the absence of
noise and occlusions) are violated. This limits their use for e.g. nighttime
sequences, which tend to contain many point light sources (including on
dynamic objects) and low signal-to-noise ratio (SNR) in darker image
regions. In this paper, we show how to use a combination of three techniques
to allow the existing photometric losses to work for both day and nighttime
images. First, we introduce a per-pixel neural intensity transformation to
compensate for the light changes that occur between successive frames.
Second, we predict a per-pixel residual flow map that we use to correct the
reprojection correspondences induced by the estimated ego-motion and depth
from the networks. And third, we denoise the training images to improve the
robustness and accuracy of our approach. These changes allow us to train a
single model for both day and nighttime images without needing separate
encoders or extra feature networks like existing methods. We perform
extensive experiments and ablation studies on the challenging Oxford
RobotCar dataset to demonstrate the efficacy of our approach for both day
and nighttime sequences.
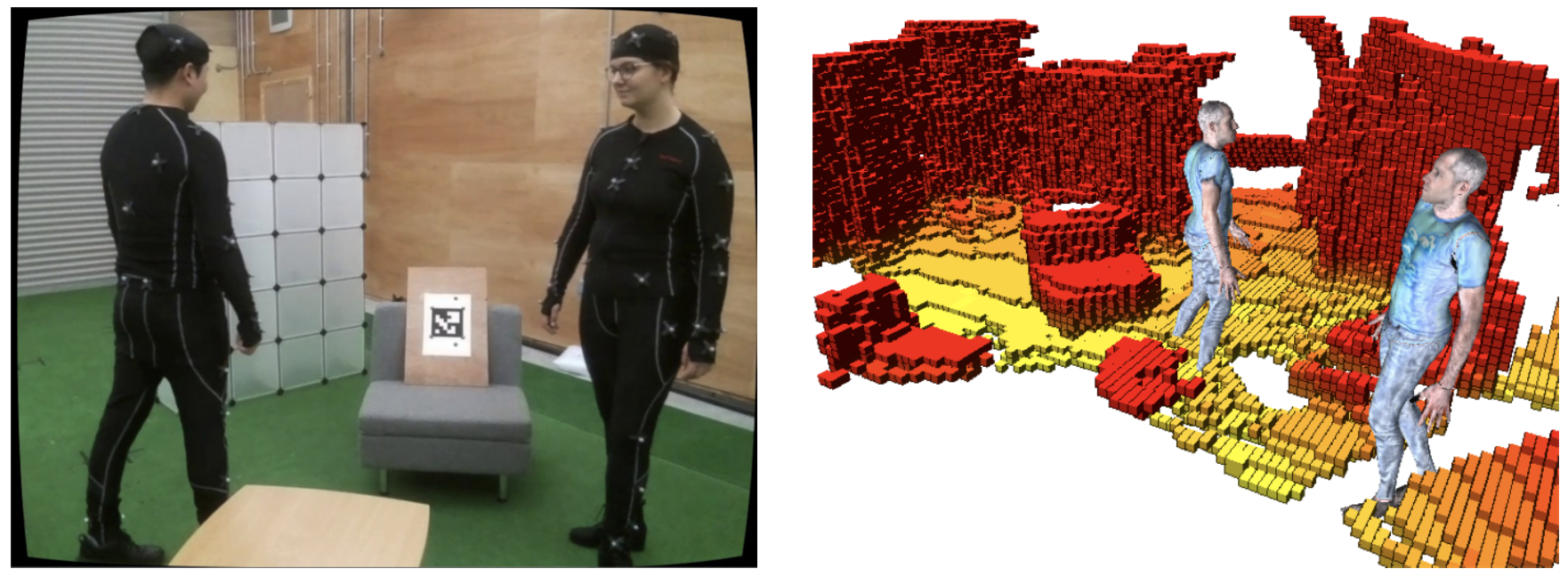
We present what is thus, to our knowledge, the first system to perform
simultaneous mapping
and multi-person 3D human pose estimation from a monocular camera mounted on a
single UAV.
Unmanned aerial vehicles (UAVs) have been used for many applications in
recent years, from urban search and rescue,
to agricultural surveying, to autonomous underground mine exploration.
However, deploying UAVs in tight, indoor spaces,
especially close to humans, remains a challenge. One solution, when limited
payload is required, is to use micro- UAVs,
which pose less risk to humans and typically cost less to replace after a
crash. However, micro-UAVs can only carry a
limited sensor suite, e.g. a monocular camera instead of a stereo pair or
LiDAR, complicating tasks like dense mapping
and markerless multi-person 3D human pose estimation, which are needed to
operate in tight environments around people.
Monocular approaches to such tasks exist, and dense monocular mapping
approaches have been successfully deployed for UAV
applications. However, despite many recent works on both marker-based and
markerless multi-UAV single-person motion capture,
markerless single-camera multi-person 3D human pose estimation remains a
much earlier-stage technology, and we are not
aware of existing attempts to deploy it in an aerial context. In this paper,
we present what is thus, to our knowledge,
the first system to perform simultaneous mapping and multi-person 3D human
pose estimation from a monocular camera
mounted on a single UAV. In particular, we show how to loosely couple
state-of-the-art monocular depth estimation and
monocular 3D human pose estimation approaches to reconstruct a hybrid map of
a populated indoor scene in real time.
We validate our component-level design choices via extensive experiments on
the large-scale ScanNet and GTA-IM datasets.
To evaluate our system-level performance, we also construct a new Oxford
Hybrid Mapping dataset of populated indoor scenes
An attempt is made to solve this problem in this paper by proposing a deep
meta-imitation learning framework
comprising of an attentive-embedding net- work and a control network, capable of
learning a new task in an end-to-end manner while requiring only one or a few
visual demonstrations
The ability to apply a previously-learned skill (e.g., pushing) to a new
task (context or object)
is an important requirement for new-age robots. An attempt is made to solve
this problem in this
paper by proposing a deep meta-imitation learning framework comprising of an
attentive-embedding
net- work and a control network, capable of learning a new task in an
end-to-end manner while
requiring only one or a few visual demonstrations. The feature embeddings
learnt by incorporating
spatial attention is shown to provide higher embedding and control accuracy
compared to other
state-of-the-art methods such as TecNet and MIL. The interaction between the
embedding
and the control networks is improved by using multiplicative
skip-connections and is shown to
overcome the overfitting of the trained model. The superiority of the
proposed model is
established through rigorous experimentation using a publicly available
dataset and a
new dataset created using PyBullet. Several ablation studies have been
carried out to justify
the design choices
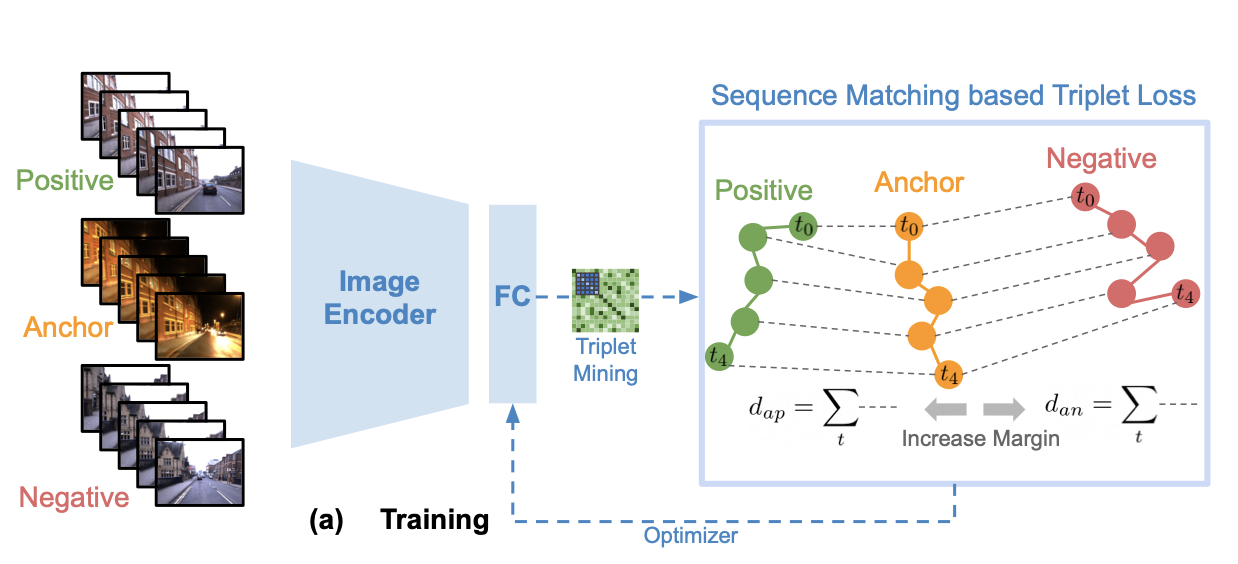
In this work, for the first time, we bridge the gap between single image
representation learning
and sequence matching through" SeqMatchNet" which transforms the single image
descriptors such
that they become more responsive to the sequence matching metric
Visual Place Recognition (VPR) for mobile robot global relocalization is a
well-studied problem,
where contrastive learning based representation training methods have led to
state-of-the-art
performance. However, these methods are mainly designed for single image
based VPR, where sequential
information, which is ubiquitous in robotics, is only used as a
post-processing step for filtering single
image match scores, but is never used to guide the representation learning
process itself. In this work,
for the first time, we bridge the gap between single image representation
learning and sequence matching
through" SeqMatchNet" which transforms the single image descriptors such
that they become more responsive
to the sequence matching metric. We propose a novel triplet loss formulation
where the distance metric is
based on" sequence matching", that is, the aggregation of temporal
order-based Euclidean distances computed
using single images. We use the same metric for mining negatives online
during the training which helps the
optimization process by selecting appropriate positives and harder
negatives. To overcome the computational
overhead of sequence matching for negative mining, we propose a 2D
convolution based formulation of sequence
matching for efficiently aggregating distances within a distance matrix
computed using single images. We show
that our proposed method achieves consistent gains in performance as
demonstrated on four benchmark datasets.
In this paper, we look into the problem of estimating per-pixel depth maps
from unconstrained RGB monocular night-time images which is a difficult
problem
that has not been addressed adequately in the literature. The state-of-the-
art day-time
depth estimation methods fail miserably when tested with night-time images
due to a large
domain shift between them. The usual photo-metric losses used for training
these networks
may not work for night-time images due to the absence of uniform lighting
which is commonly
present in day-time images, mak- ing it a difficult problem to solve. We
propose to solve
this problem by posing it as a domain adaptation problem where a network
trained with day-time
images is adapted to work for night-time images. Specifically, an encoder is
trained to generate
features from night-time images that are indistinguishable from those
obtained from day-time images
by using a PatchGAN-based adversarial discrim- inative learning method.
Unlike the existing methods
that directly adapt depth prediction (network output), we propose to adapt
feature maps obtained from
the encoder network so that a pre-trained day-time depth decoder can be
directly used for predicting
depth from these adapted features.
Hence, the resulting method is termed as “Adversarial Domain Feature
Adaptation (ADFA)” and
its efficacy is demonstrated through experimentation on the challenging
Oxford night driving dataset.
To the best of our knowledge, this work is a first of its kind to estimate
depth from unconstrained
night-time monocular RGB images that uses a com- pletely unsupervised
learning process.
The modular encoder-decoder architecture for the proposed ADFA method allows
us to use the encoder
module as a feature extractor which can be used in many other applications.
One such application
is demonstrated where the features obtained from our adapted encoder network
is shown to outperform
other state-of-the-art methods in a visual place recogni- tion problem,
thereby,
further establishing the usefulness and effectiveness of the proposed
approach.
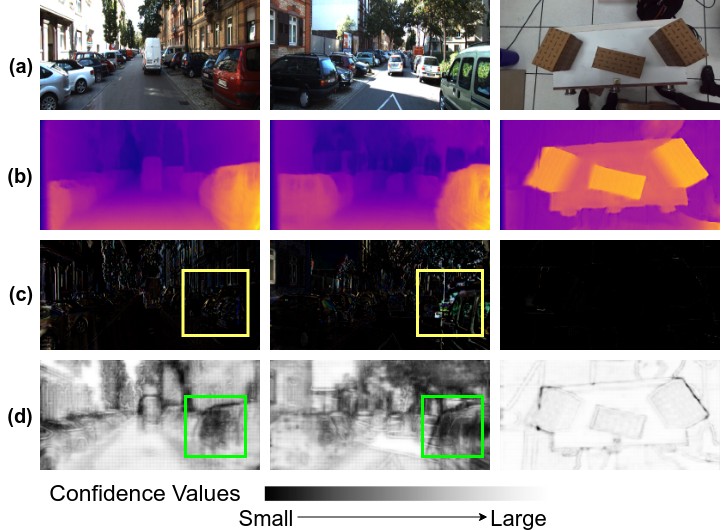
In this paper, we propose an unsupervised deep
learning framework with Bayesian inference for improving
the accuracy of per-pixel depth prediction from monocular
RGB images.
In this paper, we propose an unsupervised deep
learning framework with Bayesian inference for improving
the accuracy of per-pixel depth prediction from monocular
RGB images. The proposed framework predicts confidence map
along with depth and pose information for a given input image.
The depth hypotheses from previous frames are propagated forward
and fused with the depth hypothesis of the current frame
by using Bayesian inference mechanism. The ground truth
information required for training the confidence map prediction
is constructed using image reconstruction loss thereby obviating
the need for explicit ground truth depth information used
in supervised methods. The resulting unsupervised framework
is shown to outperform the existing state-of-the-art methods
for depth prediction on the publicly available KITTI outdoor
dataset. The usefulness of the proposed framework is further
established by demonstrating a real-world robotic pick and
place application where the pose of the robot end-effector
is computed using the depth predicted from an eye-in-hand
monocular camera. The design choices made for the proposed
framework is justified through extensive ablation studies.
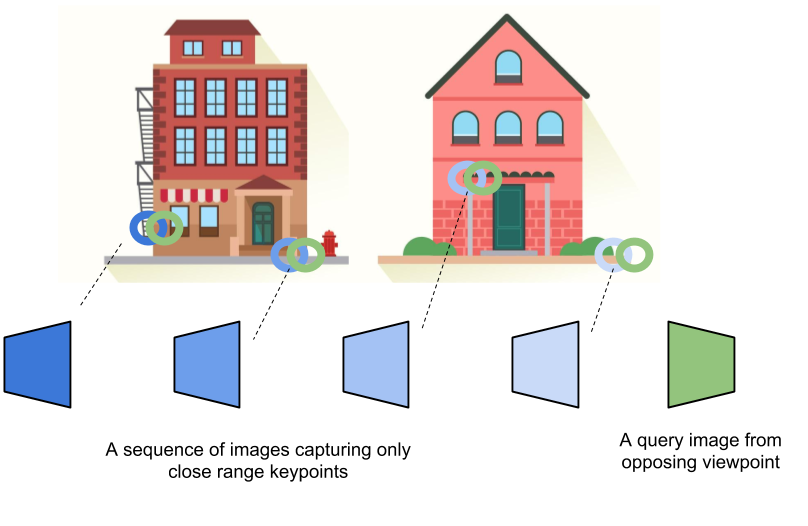
In this paper we present a new depth and temporal-aware visual place recognition
system
that solves the opposing viewpoint, extreme appearance-change visual place
recognition
problem.
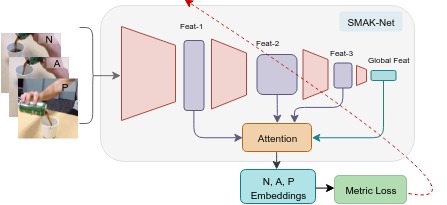
This paper proposes an end-to-end self-supervised
feature representation network named Attentive Task-Net or
AT-Net for video-based task imitation. The proposed AT-Net
incorporates a novel multi-level spatial attention module to
identify the intended task demonstrated by the expert. The
neural connections in AT-Net ensure the relevant information
in the demonstration is amplified and the irrelevant information
is suppressed while learning task-specific feature embeddings.
This is achieved by a weighted combination of multiple inter-
mediate feature maps of the input image at different stages of
the CNN pipeline. The weights of the combination are given by
the compatibility scores, predicted by the attention module for
respective feature maps. The AT-Net is trained using a metric
learning loss which aims to decrease the distance between the
feature representations of concurrent frames from multiple view
points and increase the distance between temporally consecutive
frames. The AT-Net features are then used to formulate a
reinforcement learning problem for task imitation. Through ex-
periments on the publicly available Multi-view pouring dataset,
it is demonstrated that the output of the attention module
highlights the task-specific objects while suppressing the rest
of the background. The efficacy of the proposed method is
further validated by qualitative and quantitative comparison
with a state-of-the-art technique along with intensive ablation
studies. The proposed method is implemented to imitate a
pouring task where an RL agent is learned with the AT-Net in
Gazebo simulator. Our findings show that the AT-Net achieves
6.5% decrease in alignment error along with a reduction in the
number of training iterations by almost 155k over the state-of-
the-art while satisfactorily imitating the intended task.
This paper presents a new GAN-based deep learning framework for estimating
absolute
scale aware depth and ego motion from monocular images using a completely
unsupervised
mode of learning.
This paper presents a new GAN-based deep learning framework for estimating
absolute
scale aware depth and ego motion from monocular images using a completely
unsupervised
mode of learning. The proposed architecture uses two separate generators to
learn the
distribution of depth and pose data for a given input image sequence. The
depth and pose data,
thus generated, are then evaluated by a patch-based discriminator using the
reconstructed
image and its corresponding actual image. The patch-based GAN (or PatchGAN)
is shown to
detect high frequency local structural defects in the reconstructed image,
thereby
improving the accuracy of overall depth and pose estimation. Unlike
conventional GANs,
the proposed architecture uses a conditioned version of input and output of
the generator
for training the whole network. The resulting framework is shown to
outperform all existing
deep networks in this field, beating the current state-ofthe-art method by
8.7% in absolute
error and 5.2% in RMSE metric. To the best of our knowledge, this is first
deep network based
model to estimate both depth and pose simultaneously using a conditional
patch-based GAN paradigm.
The efficacy of the proposed approach is demonstrated through rigorous
ablation studies and
exhaustive performance comparison on the popular KITTI outdoor driving
dataset.
In this paper we present a new depth and temporal-aware visual place recognition
system
that solves the opposing viewpoint, extreme appearance-change visual place
recognition
problem.
Visual place recognition (VPR) - the act of recognizing a familiar
visual place - becomes difficult when there is
extreme environmental appearance change or viewpoint change.
Particularly challenging is the scenario where both phenomena
occur simultaneously, such as when returning for the first time
along a road at night that was previously traversed during the
day in the opposite direction. While such problems can be solved
with panoramic sensors, humans solve this problem regularly
with limited field of view vision and without needing to constantly turn
around.
In this paper we present a new depth- and
temporal-aware visual place recognition system that solves the
opposing viewpoint, extreme appearance-change visual place
recognition problem. Our system performs sequence-to-single
matching by extracting depth-filtered keypoints using a stateof-the-art
depth
estimation pipeline, constructing a keypoint
sequence over multiple frames from the reference dataset, and
comparing those keypoints to those in a single query image.
We evaluate the system on a challenging benchmark dataset
and show that it consistently outperforms a state-of-the-art
technique. We also develop a range of diagnostic simulation
experiments that characterize the contribution of depth-filtered
keypoint sequences with respect to key domain parameters
including degree of appearance change and camera motion.
This paper presents a deep network based unsupervised visual odometry system for
6-DoF camera pose estimation and finding dense depth map for its monocular view
This paper presents a deep network based unsupervised visual odometry system
for 6-DoF camera pose estimation and finding dense depth map for its
monocular view. The
proposed network is trained using unlabeled binocular stereo
image pairs and is shown to provide superior performance in
depth and ego-motion estimation compared to the existing stateof-the-art.
This is achieved by introducing a novel objective
function and training the network using temporally alligned
sequences of monocular images. The objective function is based
on the Charbonnier penalty applied to spatial and bi-directional
temporal reconstruction losses. The overall novelty of the
approach lies in the fact that the proposed deep framework
combines a disparity-based depth estimation network with
a pose estimation network to obtain absolute scale-aware 6-
DoF camera pose and superior depth map. According to our
knowledge, such a framework with complete unsupervised endto-end
learning has not been tried so far, making it a novel
contribution in the field. The effectiveness of the approach is
demonstrated through performance comparison with the stateof-the-art
methods on KITTI driving dataset
This paper presents a deep network based unsupervised visual odometry system for
6-DoF camera pose estimation and finding dense depth map for its monocular view
This paper looks into the problem of precise
autonomous landing of an Unmanned Aerial Vehicle (UAV)
which is considered to be a difficult problem as one has
to generate appropriate landing trajectories in presence of
dynamic constraints, such as, sudden changes in wind velocities
and directions, downwash effects, change in payload etc. The
problem is further compounded due to uncertainties arising
from inaccurate model information and noisy sensor readings.
The problem is partially solved by proposing a Reinforcement
Learning (RL) based controller that uses Least Square Policy
Iteration (LSPI) to learn the optimal control policies required
for generating these trajectories. The efficacy of the approach
is demonstrated through both simulation and real-world experiments
with actual Parrot AR drone 2.0. According to our
study, this is the first time such experimental results have been
presented using RL based controller for drone landing, making
it a novel contribution in this field
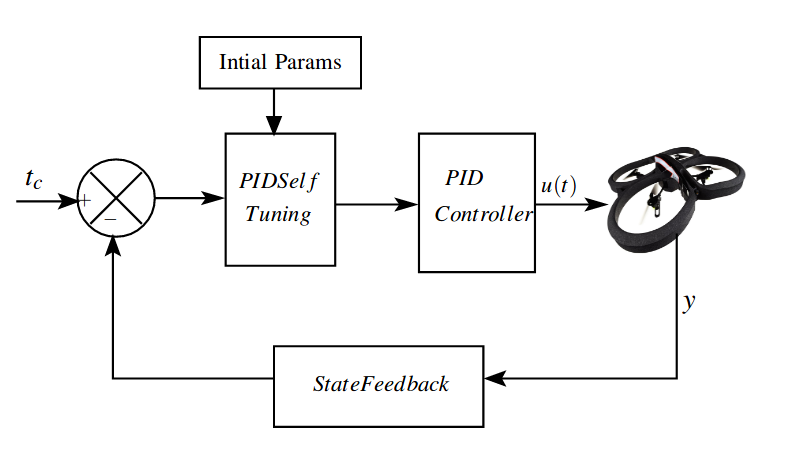
In this paper, a gradient decent based methodologyis employed to tune the
Proportional-Integral-Derivative
(PID)controller parameters for AR Drone quadrotor.
In this paper, a gradient decent based methodology is employed to
tune the Proportional-Integral-Derivative (PID) controller parameters
for AR Drone quadrotor. The three PID controller parameters, proportional
gain (Kp), integral gain (Ki) and derivative gain (Kd) are tuned online
while flying.
The proposed technique has been demonstrated through two test cases.
One is the way-point navigation and other is the leader-follower formation
control.
The experimental result as well as simulations result have shown for both
the cases.
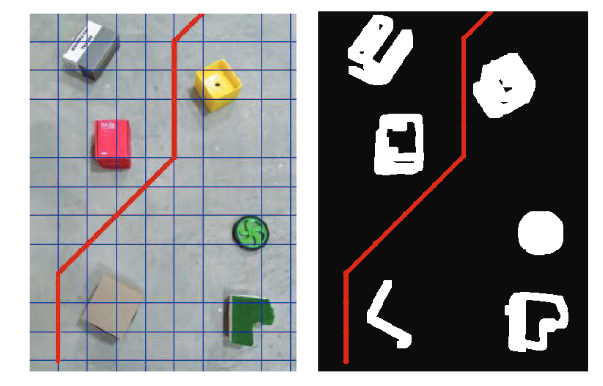
The main objective of this paper is to develop an autonomous robot that
show the use of Q-learning for navigation in a complete unknown environment.
This will calculate the shortest path from current state to goal state by
analyzing
the environment through captured images. Further the captured images will be
processed
through image processing and machine learning techniques. The proposed
method also takes
care of the obstacles present in that environment. Initially, the unknown
environment
will be captured using a camera. Obstacle detection method will be applied
on it.
Then the grid based map obtained from vision based obstacle detection method
will
be given to Q-Learning algorithm which will be further made live with motion
planning.